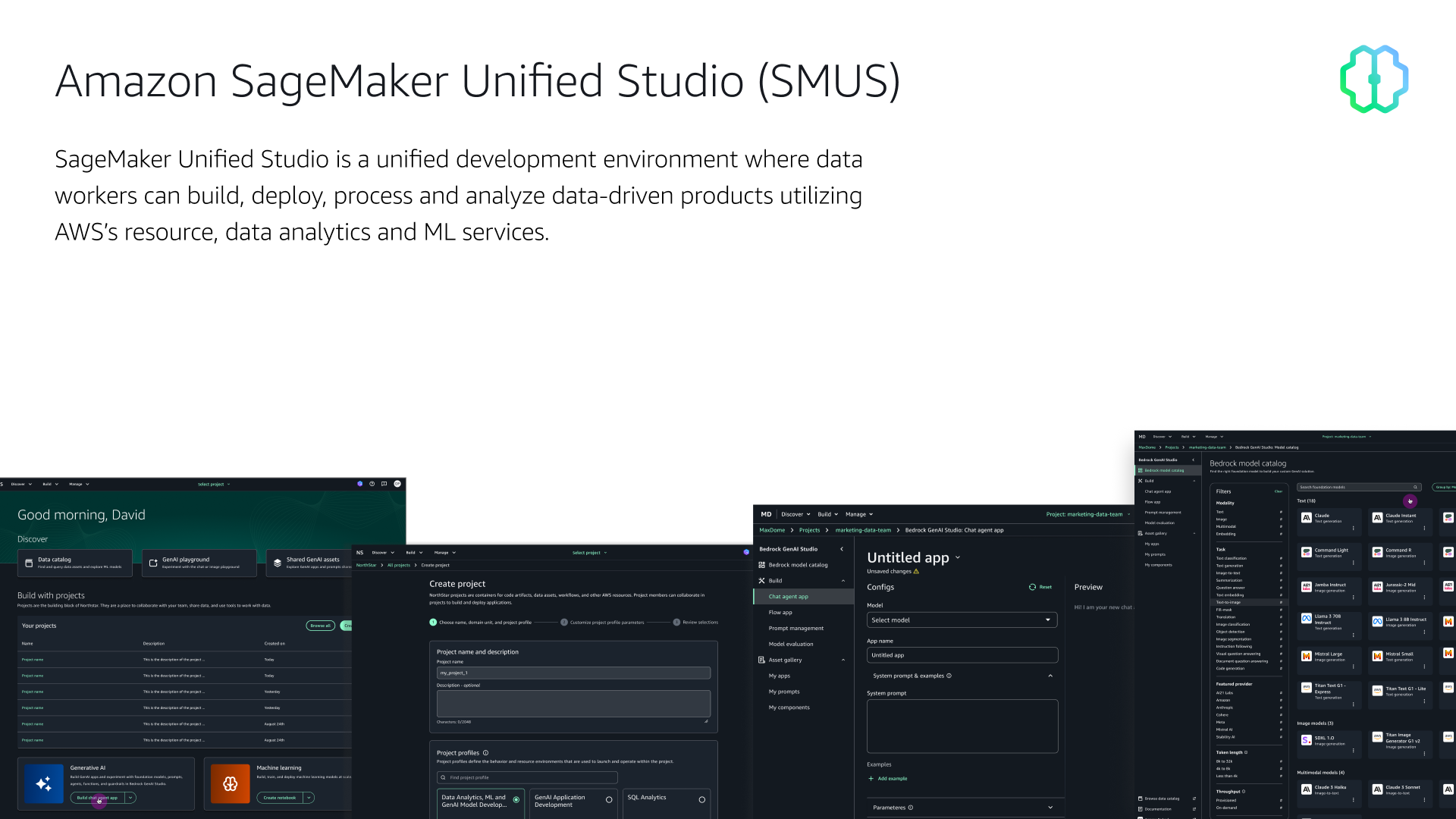
SMUS is where data teams go to do their actual work. It consolidates familiar AWS tools (Amazon EMR, Glue, Athena, Redshift, Bedrock, and SageMaker AI) into a single governed environment, so teams don't have to jump between disconnected consoles to get things done.
In practice, that means a data engineer can query a data lake, a machine learning engineer can train and deploy a model, and a GenAI builder can create a Bedrock-powered application, all from the same place, within the same project, with access to the same data.
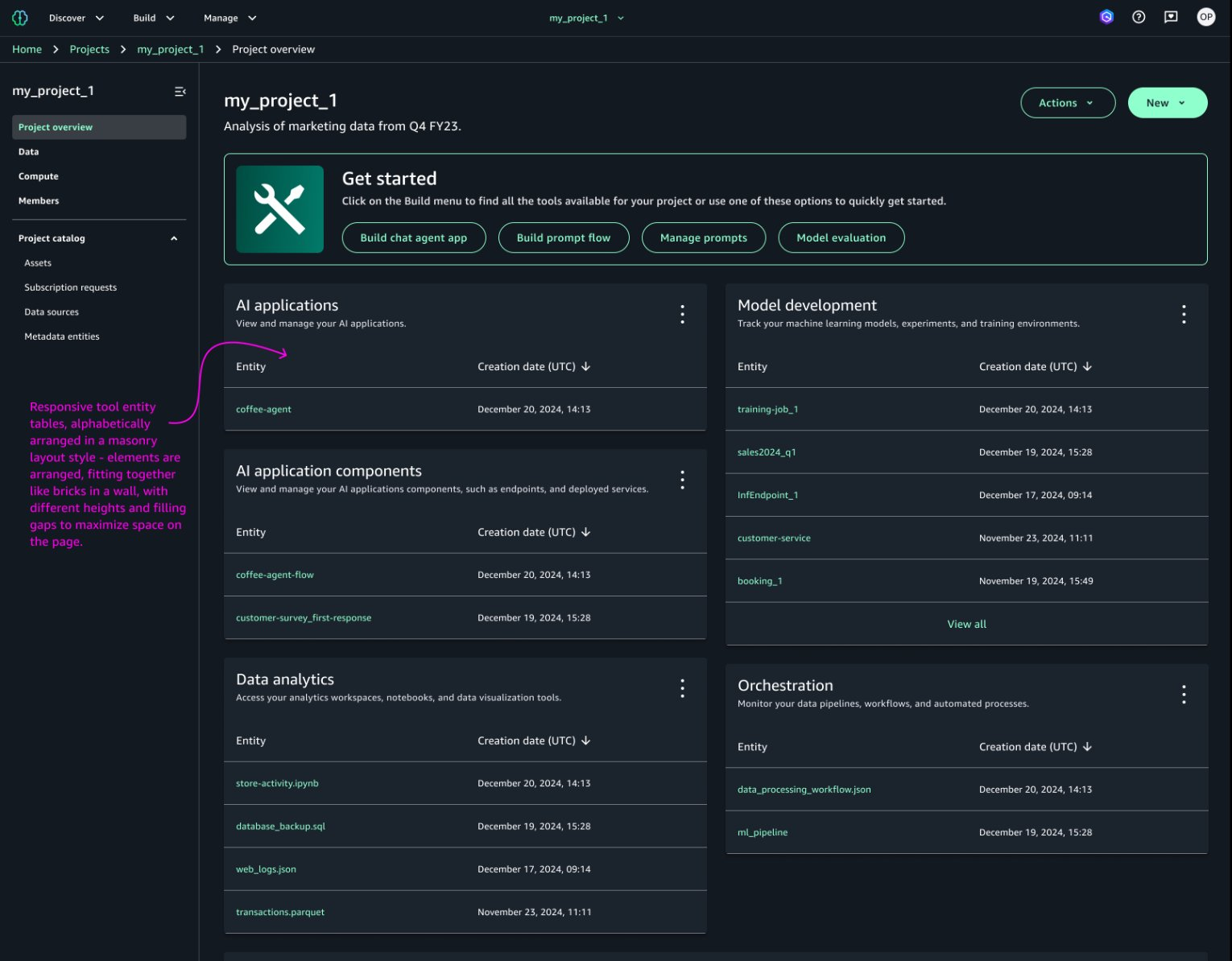
Work is organized into projects: shared spaces where team members collaborate, create artifacts, and share analytics and AI assets across the organization. Each project is scoped to a set of tools (defined by its project profile), and everything a team builds (notebooks, pipelines, prompts, models, applications) lives inside that project.
The core use cases span four areas: SQL analytics for querying and exploring data, data processing for building ETL pipelines and workflows, model development for training and deploying ML models, and generative AI for building applications powered by Amazon Bedrock. These workflows increasingly overlap, which is exactly why a unified environment exists in the first place.